AIファクトリーを強化へ:EPCのGaNソリューションがNVIDIA MGXアーキテクチャをいかに強化するか
デジタル世界は新たなAI産業革命に入っており、データセンターは大規模なインテリジェンスを生成するAIファクトリーへと変化しています。AIは、もはやソフトウエアだけの話ではなく、急速にインフラの話になってきています。現代の作業負荷は、人間とAIの単純なやり取りから、AI同士の協調へと移行しており、エージェント・モデルが作業量を調整し、自律的に推論し、非常に長いトークン・シーケンス(最小単位の羅列)にわたって作業します。これによって、インフラに新たな圧力がかかります:システムはより多くの生のコンピューティング能力を必要とするだけでなく、待ち時間、熱管理、エネルギー効率に関する厳しい要件も満たす必要があります。AIファクトリーが実際にどのように構築されているかを理解するために、米NVIDIA(エヌビディア)のMGX™は、拡張性と柔軟性に優れた高速コンピューティング・インフラのためのモジュール式基盤を提供します。MGXは、インフラのモジュール性と迅速な展開に対応していますが、より深刻なボトルネックが別の場所で発生しています:それは電力供給です。AIシステムが、より複雑で高密度になるにつれて、性能と効率を維持するためには、電力変換の効率が重要になります。重要な基盤技術の1つは、Efficient Power Conversion(EPC)の窒化ガリウム(eGaN®)・ソリューションであり、次世代AIインフラに必要な効率性、電力密度、熱特性を提供します。
NVIDIA MGX:高速コンピューティングのためのモジュール式インフラ
NVIDIA MGXは、新しいアクセラレータ世代ごとにハードウエアを完全に再設計する必要はなく、シングル・ノード・サーバー、ラック規模のシステム、ポッド・レベルの展開、完全なAIデータセンター・インフラまでを網羅するオープンなモジュール式リファレンス・アーキテクチャを提供します。
OEM(相手先ブランドによる生産)やODM(相手先ブランドによる設計・生産)は、各用途ごとに新しいプラットフォームを構築する代わりに、CPU、GPU、ネットワーク、データ処理ユニット(DPU)のさまざまな組み合わせをサポートする標準化されたアーキテクチャ・フレームワークを活用できます。
このモジュール式アプローチによって、非反復エンジニアリング(NRE:non-recurring engineering)コストが大幅に削減され、市場投入までの期間が数カ月短縮されます。共通のハードウエア「DNA」によって、パートナ企業は、複数世代の高速コンピューティング・プラットフォームにわたって設計要素を再利用できるため、投資対効果(ROI:return on investment)が向上し、システムの迅速なカスタマイズが可能になります。MGXは、x86およびArmベースのサーバー・アーキテクチャやデータ伝送規格PCIeなどの業界標準に最適化されており、幅広い互換性を実現しています。
NVIDIA MGXの際立った特徴は、その柔軟性です。NVIDIAによると、このアーキテクチャは100種類以上の標準システム構成をサポートしており、エンタープライズ・サーバーから大規模なAIインフラへと、全面的な再設計なしに拡大できる拡張可能な設計を実現できます。ただし、AIのコンピューティング密度が拡大し続けるにつれて、モジュール性だけでは、もはや十分ではありません。この課題は、急速に増大する熱負荷とコンピューティング負荷に対応するために、電力を効率的に供給することに急速にシフトしています。
エージェント型AI向け第3世代MGXラック・アーキテクチャ
ラック・レベルでは、NVIDIA Vera Rubinプラットフォームと同時に発表された第3世代NVIDIA MGXアーキテクチャは、エージェント型AIシステムの急に出てきた要件に対応するために特別に構築されています。これらの作業負荷には、高スループットの推論、低遅延の相互接続、高密度なCPUサンドボックス(通常利用する領域から隔離した保護された空間)、キー・バリュー・キャッシュ(大規模言語モデルが文章を生成する際の処理を高速化する技術)の拡張と継続的な推論ワークフローのための大容量メモリーが必要です。
第3世代のNVIDIA MGXラックは、機械設計、電力分配、熱管理において数々の技術的進歩を遂げています。完全モジュール式のプリント回路基板ベースのラックは、従来のケーブル、ホース、システム・ファンを不要にし、ケーブルなし、ファンなしのコンピューティング環境を実現します。NVIDIA NVLinkスイッチ・トレイは、ラックの機能を中断することなく交換できるため、大規模導入における回復力と保守性が向上します。
もう一つの重要なイノベーションは、電力最適化です。ダイナミック・パワー・ステアリングによって、どの時点においても、システムは作業負荷の要件に基づいて、CPU、GPU、NVLinkサブシステムの間で利用可能な電力をインテリジェントに分配できます。さらに、ラック・レベルのコンデンサは、AI推論やトレーニング作業負荷でよく発生する突然の電力スパイクを抑制するために役立ちます。このシステムは、100%液冷式で、最大45℃の温水入口温度で動作できるため、電力使用効率(PUE:power usage effectiveness)が低減されるので余分な冷却電力負担を減らせ、コンピューティングにより多くのエネルギーを割り当てることができます。
直流800 Vの電源アーキテクチャへの戦略的移行
AIインフラに対するNVIDIAの戦略における重要な要素は、直流800 Vの電源アーキテクチャの採用です。ラックの電力密度が高まるにつれて、次世代高速コンピューティングの課題は、従来の交流ベースの電力供給システムの経済的な実現可能性になっています。NVIDIAの直流800 Vのアプローチは、電力変換段の段数を減らし、直流の電力分配をラックにより近づけることで、効率性を向上させ、データセンター・インフラを単純化ます。
重要な点として、このアーキテクチャは、前方拡張性と後方互換性の両方を備えています。新しいAIファクトリーは、エンド・ツー・エンドの直流800 Vの電力分配を活用してエネルギー効率を最大化することができ、既存の施設では、土地、電力インフラ、建物の外郭への既存の投資を無駄にすることなく、MGX互換の電源ラックを備えたハイブリッド・アーキテクチャに展開できます。このアーキテクチャは、分散型バッテリー・バックアップ・システムをサポートしており、耐障害性を向上させ、より高密度なコンピューティング環境への展開を可能にします。
GPUの電力要件は、NVIDIA Blackwellアーキテクチャの1000 Wから、将来のFeynmanクラスGPUで予測される6000 Wへと拡大しており、従来の直流48 Vの電力分配は物理的な限界に達しつつあります。NVIDIA Vera Rubinサーバー基板1枚に48 Vで12 kWの電力を供給するためには250 Aの電流が必要となり、これは標準的なコネクタでは非現実的で、非常に大きな銅損が発生します。
この高電圧電力分配を実現するために、3つの主要なアーキテクチャ・オプションが登場しています。いずれもEfficient Power Conversion(EPC)のGaN技術を利用しています:
- 直流800 Vから直流48 V:この方式では、800 Vから48 Vへの小型コンバータを、多くの場合、電力分配基板(PDB:Power Distribution Board)上、またはサーバーの各部に配置します。これによって、サーバー基板上の従来の48 Vのハードウエアを引き続き使えるため、より高い電力レベルへの移行が容易になります。
- 直流800 Vから直流12 V:サーバー基板上で800 Vを直接12 Vに変換することで、低電圧バスと比べて電力分配損失が1/4に削減できます。このアーキテクチャでは、100 Vまたは150 VのGaNデバイスを使った8段ISOP構成を採用し、多くの場合、「NVLink radius」内で高密度を実現できます。
- 直流800 Vから直流6 V:これは、プロセッサが必要とする1 V以下の電圧レベルへの単段変換において、高効率な経路となります。基板上の電力分配損失は増加しますが、変換段の段数を最小化できます。この構成には、大電流の負荷点(POL:point-of-load)変換向けに特別に設計したEPCの最新の低電圧GaNトランジスタが貢献します。
直流800 から直流48 Vへ
次世代AIの電源供給において最も現実的なアプローチの一つは、小型絶縁型コンバータを使って直流800 Vを直流48 Vに降圧することです。このコンバータは通常、電力分配基板(PDB)上、またはサーバー・ラック内部に配置されます。このアーキテクチャは、既存の48Vのサーバー・エコシステムをサポートし、ハイパースケーラ(クラウド・サービスを大規模に構築・運用する企業)やOEM(相手先ブランドによる生産企業)は、成熟したインフラを活用し、ラックの電力密度を大幅に向上させることができます。
システム的な観点から見ると、48 Vの中間バスは、効率性、電流処理能力、アーキテクチャの柔軟性の間で効果的なトレードオフとなります。これによって、設計者は、既存のサーバー基板の構成と使い慣れた48 Vの電力分配層を、既存のハードウエア・エコシステムへの影響を最小化して活用できる利点があります。
ただし、半導体レベルでは、この段では、高いスイッチング周波数と高い電力密度を備え、かつ過度の熱損失のないデバイスが求められます。EPC2376などの150 V のGaN FETが、ISOPの1次側と2次側の両方においてベンチマークとなるソリューションを提供できます。シリコンMOSFETと比べて、これらのデバイスは、スイッチング損失が劇的に低く、逆回復電荷がほとんどなく、電力密度も優れているため、より小型の磁気部品、より高い動作周波数、より小型なコンバータ実装が可能になります。
直流800 Vから直流12 Vへ
もう一つのより積極的なアプローチは、直流800 Vをサーバー基板上で直接、直流12 Vに変換するアーキテクチャで、中間変換ステップの数を大幅に削減でき、システム全体の効率を向上できます。最も直接的な利点は電力分配にあります:高電圧で動作させることで電流が大幅に減少し、導通損失は低電圧バス・アーキテクチャに比べて1/4になります。
この構成は特に、AIアクセラレータにとって魅力的です。AIアクセラレータでは、電力供給を厳しい物理的制約の下で実施する必要があり、特にいわゆる「NVLink radius」内では、寄生損失を最小化し、過渡的な性能を維持するためにGPUと近接させることが重要となります。
要求される電力密度と熱特性を得るために、EPCは、8段構成の入力直列出力並列(ISOP)アーキテクチャを推奨しています。この構成によって、複数段にかかる電圧ストレスが軽減され、1次側に150 VのGaNデバイス、2次側にEPC2366などの40 Vデバイスを使えるようになります。これらのデバイスは本質的に、高電圧デバイスの対応品に比べて、スイッチング特性が向上し、導通損失が低減されます。ISOPのアプローチは、半導体の効率の最適化に加えて、トランスの実装を容易にし、位相インタリーブを改善し、出力容量を低減し、システム全体への放熱の均一化を実現します ーー これらはすべて、電力制約がますます厳しくなるAIサーバー環境において重要な利点となります。
直流800 Vから直流6 Vへ
性能を最優先する用途では、直流800 Vから直流6 Vへの直接変換は、最終的に1 V以下の電源電圧を必要とする最新のAIプロセッサへの電力供給において、非常に効果的な方法となります。このアーキテクチャは、単一の絶縁段で最終動作電圧に近づけることで、変換の複雑さを最小限に抑え、中間パワー段の数を削減し、エンド・ツー・エンドの効率を向上させる可能性があります。
ただし、このトレードオフは、基板上の電力分配にあります。バス電圧が低いと、電流レベルが大きくなり、プリント回路基板の配線や相互接続における導通損失が増加します。したがって、このアーキテクチャが実用するためには、極めて高効率な局所的な電力変換が必要となります。
まさにここで、次世代の低電圧GaNトランジスタが重要な役割を果たします。EPCの最新の25 Vと15 VのGaN FETであるEPC2379とEPC2378は、大電流負荷点(POL)変換に最適化しており、超低オン抵抗、逆回復電荷ゼロ、MHz帯まで高められる周波数での優れたスイッチング特性を実現します。これらの特性によって、GPUやAIアクセラレータに要求される超低電圧を高効率に供給すると同時に、高い電力密度と高速な過渡応答を維持できる小型な大電流POLレギュレータが実現できます。
EPCのGaN:ISOPコンバータの技術的基盤
直流800 Vの電力分配電圧とコンピューティング・レベルの電圧との間のギャップを埋めるためには、絶縁段は、非常に高効率かつ薄型でなければなりません。複数のモジュール型LLC共振コンバータの入力段を直列に接続することで、800 Vのストレスを複数の段に分散させるので、低電圧GaN FETが使えるようになります。
GaNを使った8段のISOPがベンチマークとして選ばれる理由:ISOP構成で8個のモジュールを使うことで、従来の単段設計に比べていくつかの技術的な利点が得られます:
- 優れた半導体性能:低電圧GaN FETは、性能指数(FoM:Figures of Merit)がはるかに優れています。例えば、EPC2381(第7世代)の100 Vデバイスは、わずか0.8 mΩのオン抵抗RDS(on)を実現しています。
- 熱および電気的な分散:変換を8段に分散させることで、プリント回路基板全体への熱分散が改善され、トランスの設計も簡素化できます。
- インタリーブによるリップル低減:複数のモジュールをインタリーブした位相で動作させることで、出力電流のリップルを大幅に低減し、リップル周波数を高めることができます。これによって、大型でかさばる出力コンデンサの必要性が軽減されます。
- 極めて高い密度:EPCの表面実装GaNデバイスは、非常に薄い(通常、わずか8mm)コンバータを実現可能で、Rubinクラスのシステムに必要な高度な液冷式コールド・プレートとの互換性を確保しています。
この実用的な実装例には、直流800 Vを直流12.5 Vに変換する6 kWのISOPベースのDC-DCコンバータであるEPC91123があります。この設計では、5000 mm2以下の基板面積で、ピーク効率98.3%、全負荷効率97%を実現しています。研究室でのテストでは、このアーキテクチャが最大500 Aの入力電流と出力電流を自然な電圧バランスで処理できることが確認されており、複雑な制御ループは不要です(図1と図2)。

図1:評価基板EPC91123
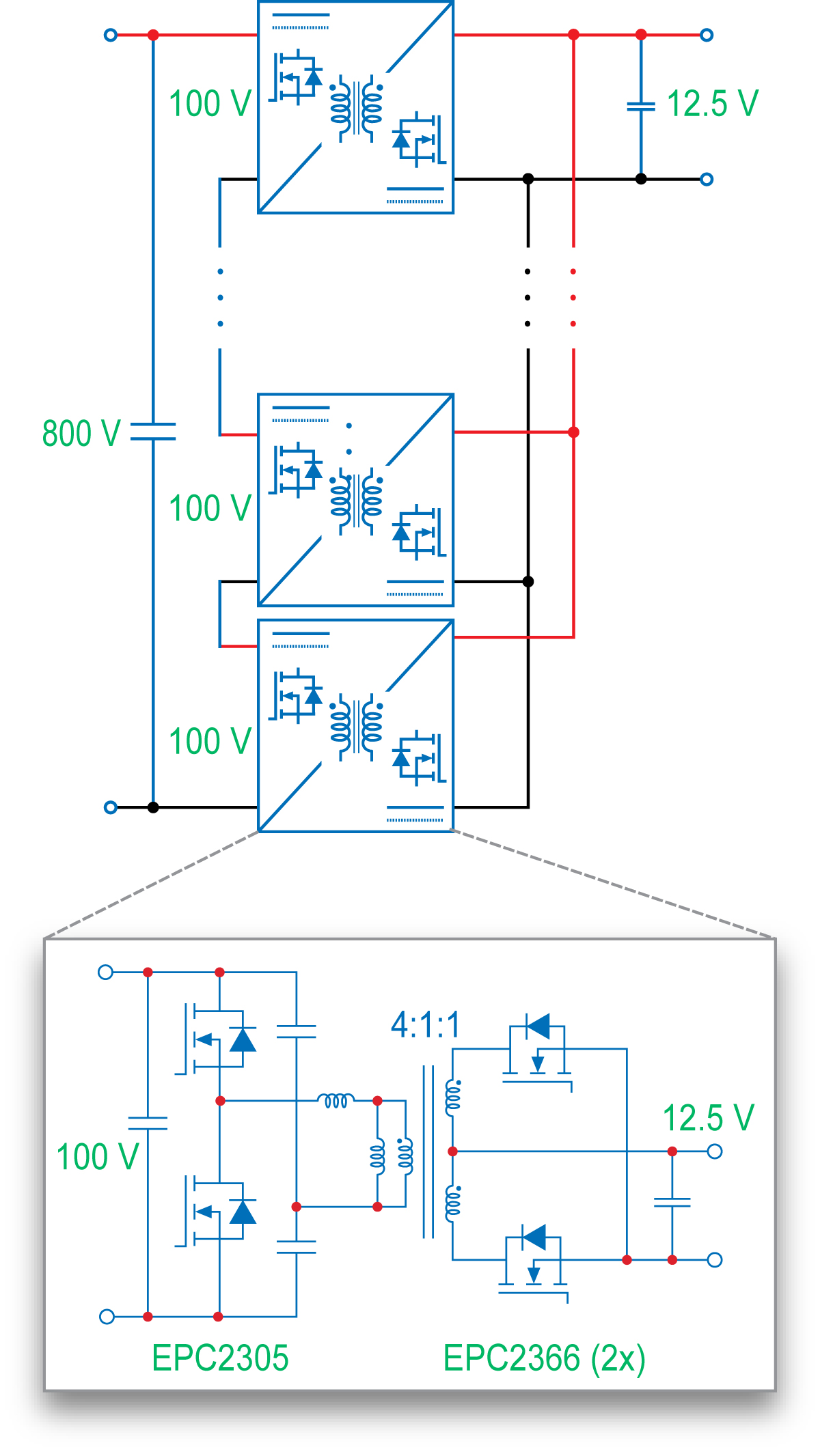
図2:ISOPコンバータの回路ブロック図
中間バス変換の再考
EPCは、中間バス・レベルで、48 Vレールを12 Vまたは6 V出力に変換するためのコンバータの競合するアプローチを検討しており、特にLLC共振コンバータとハイブリッド・スイッチド・キャパシタ(HSC:hybrid switched capacito)構成に焦点を当てています。
EPCは、48 V入力、12 V出力への電圧変換において、HSCアーキテクチャに比べて変圧器がシンプルで巻線数も少ないという利点があるタイプIのLLCアーキテクチャを推奨して採用しています。この推奨は、タイプIのLLC構成は、高効率を維持しながら、1次側巻線数、巻数比、さらには複雑さを軽減できるという実際の磁気部品の実現性に基づいています。このような軽減は、磁気損失と変圧器のサイズがボトルネックになりつつある電力密度の高いAIシステムにとって重要です。
同時に、低電圧変換段においても、下流のPOLコンバータの効率と密度を高めるために、25 Vおよび15 VのGaNデバイスへの移行が進んでいます。
POL変換:効率を巡る最終決戦
電力供給の最終段階、つまりGPUやAIアクセラレータに電力を供給するPOLレギュレータは、おそらくGaNが最大の利点を発揮する部分です。
EPCは、大電流POL用途向けに最適化した25 VのGaNトランジスタであるEPC2371を製品化しました。このデバイスの特徴は以下です:
- 標準オン抵抗RDS(on) 0.65 mΩ
- 連続電流能力 88 A
- パルス電流処理 412 A
- ゲート電荷 17 nC
- 逆回復電荷 0 nC
- 面積が2.6 mm×3.3 mmと小さい
スイッチング周波数700 kHz、出力0.8 Vでの効率試験では、制御された気流条件下でヒートシンクを使わない場合でも、十分な負荷範囲において90%を超える変換効率が示されました。これらの結果は、GaNが現代のAI負荷に必要な高いスイッチング周波数においても高い効率を維持できることを示しています。
超低電圧用途向けに、EPCの15 VのGaN FETであるEPC2370は、0.28 mΩという極めて低い抵抗値を実現し、高い電流密度にも対応し、性能をさらに向上させています。2 MHzを超えるスイッチング周波数でも、効率はベンチマーク・レベルに達しており、GaNが、より高いスイッチング周波数とより小さな受動部品サイズを同時に実現できることを裏付けています。
これによって、AIサーバー設計者は、プリント回路基板の面積を大幅に削減し、過渡応答を改善し、冷却コストを低減するチャンスを得ることができます。
結論
AIファクトリーの規模拡大が続く中、EPCはすでに、第8世代技術で未来を見据えています。2027年後半に登場予定のこれらの次世代デバイスは、3~5 MHzの高密度POLソリューションを実現でき、高電圧の電力分配とGPUの間のギャップをさらに縮めます。NVIDIA MGXのモジュール式柔軟性とEPCのGaNソリューションを組み合わせることで、業界は最終的に、次世代AIに必要なエネルギー効率の高いメガワット級のラックを提供できるようになります。
参考文献
GaN Power Devices for Efficient Power Conversion, Fourth Edition - by Alex Lidow, Michael de Rooij, John Glaser, Alejandro Pozo Arribas, Shengke Zhang, Marco Palma, David Reusch, Johan Strydom.
M. Di Paolo Emilio, The Architectural Imperative of 800 VDC in Next-Generation AI Factories - Data Centre Digest
M. Di Paolo Emilio, Powering the AI Factory: The Role of 800 VDC Distribution and ISOP Converters in Next-Generation Data Centers – Data Centre Digest
Huntington, J.; Tu, M., “800 VDC Architecture for Next-Generation AI Infrastructure,”
NVIDIA White Paper, 2025.